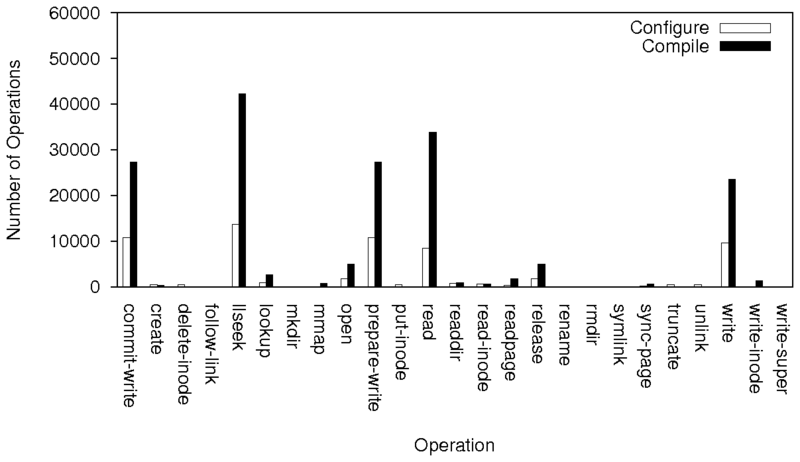
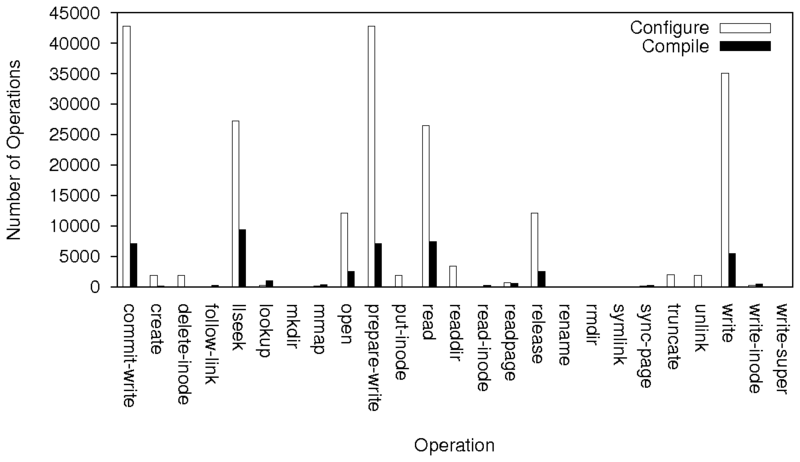
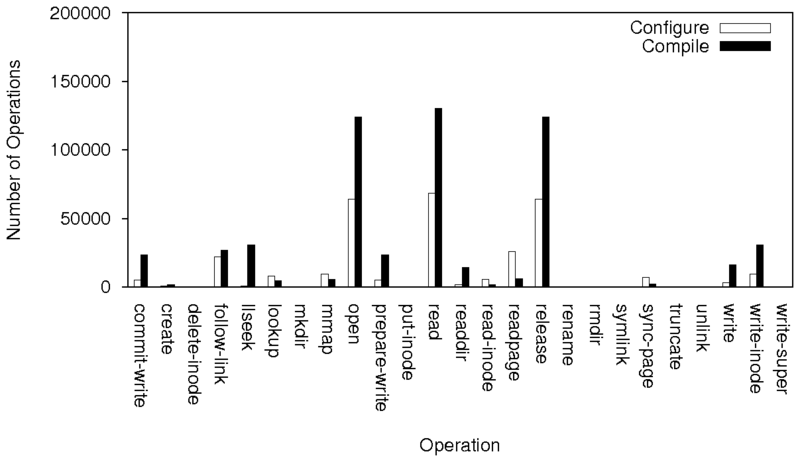
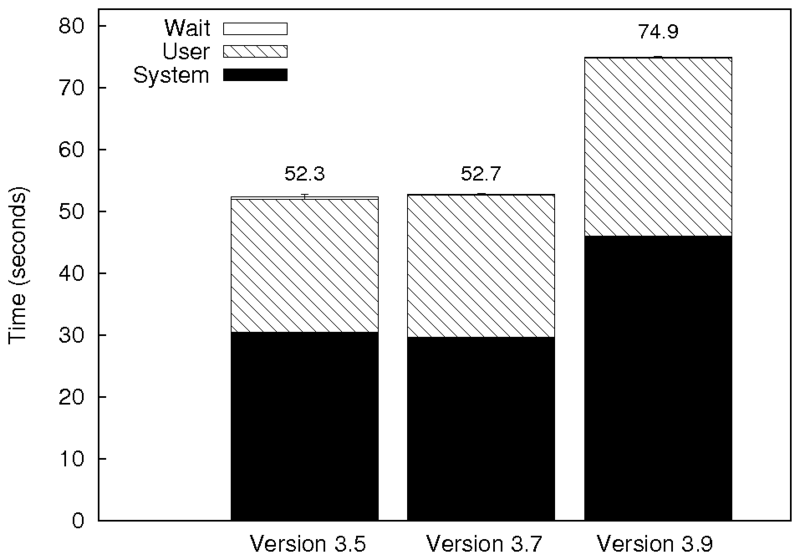
|
The two underlying themes are:
- Explain exactly what you did:
For example, if you decided to create your own benchmark, describe it
in detail. If you are replaying traces, describe where they are from,
how they were captured, and how you are replaying them (what tool?
what speed?). This can help others understand and validate your
results.
- Do not just say what you did, but justify why
you did it that way:
For example, while it is important to note that you are using ext2 as
a baseline for your analysis, it is just as important (or perhaps even
more important) to discuss why it is a fair comparison.
Similarly, it is useful for the reader to know why you ran
that random-read benchmark so that they know what conclusions to draw
from the results.
|
|