| (1) |
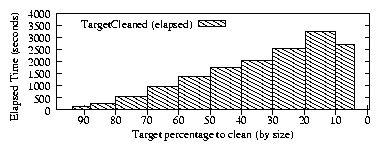
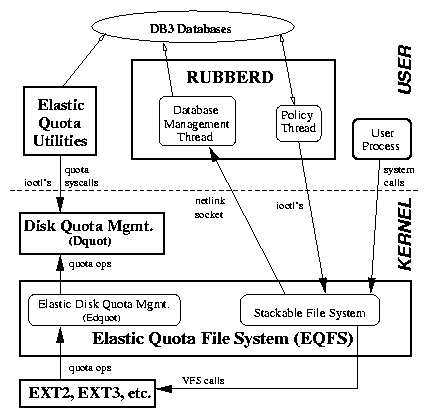
global rm size ~ .bak core .tmp user gzip mtime user_profile rm atime .o user_profile lossy atime .jpg .mpg .mp3 .aviThe first line starts a simple global policy that will delete obviously unnecessary elastic files such as backup files used by editors. When Rubberd tries to reclaim space, it will try to bring the system down to the goal level by this first policy line. If that is insufficient, Rubberd will proceed and apply the second policy line, which defines a per-user policy that will compress all elastic files. Next, Rubberd will perform a user policy that removes compiler object files that have not been read in a while, but allows users to override the system defaults. Finally, if still not enough space has been reclaimed, Rubberd will apply a lossy compression policy on multimedia files, again allowing users to override the default selection based on atime. The Rubberd configuration file (rubberd.conf) is simple and defines the parameters described in Table 1.
| Parameter | Meaning |
| hi_watermark N | % disk usage to begin cleaning |
| lo_watermark N | % disk usage to stop cleaning |
| statfs_interval S | disk usage check interval (sec) |
| mount_point M | name of EQFS mount to monitor |
| netlink on|off | process netlink messages? |
| abuse_cur M | mode to compute current usage |
| abuse_avg I N | linear historical abuse factors |
| abuse_exp I D | exponential historical abuse factors |
| Entry | Meaning |
| class/foo.tgz | a relative pathname to a file |
| ~/misc | a non-recursive directory |
| ~/tmp// | a recursive directory |
| src/eqfs/*.o | all object files in a specific directory |
| src//*.o | all object files recursively under src |
| ~//*.mp3 | all MP3 files anywhere in home dir. |