page->mapping = lower_inode->i_mapping;
err = lower_inode->i_mapping->a_ops->
readpage(lower_file, page);
page->mapping = upper_inode->i_mapping;
We analyzed the Linux kernel functions that directly or indirectly use
inode and cache page connectivity and found that in all these cases,
the above modification works correctly. We tested the resulting
stackable file system on a single-CPU and multi-CPU machines under the
compile and I/O-intensive workloads. No races or other problems were
observed.
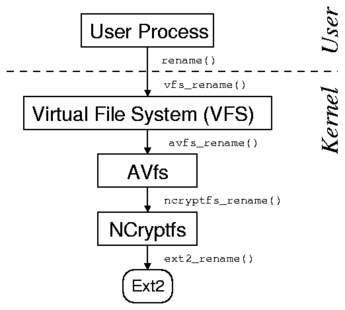
Another problem specific for fan-out stackable file systems is the sequential
execution of VFS requests. It dramatically increases latency
of VFS operations that require synchronous accesses to several branches.
For example, RAIF5 synchronously reads data and parity pages before a
small write operation can be initiated.
This problem is related to the previous one because
sometimes, the data pages should be shared not only between lower
and upper file systems but also between several lower file systems
and an upper one.
We are currently working on this problem.
However, it is important to understand that it only increases the latency
of certain file system operations while this has little impact on the aggregate
RAIF performance under a workload generated by many concurrent processes.
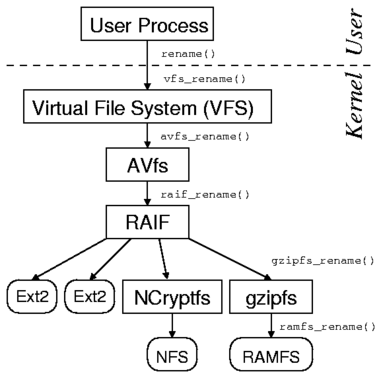
Our current development efforts are concentrated on the performance
enhancements of the general fan-out templates.
In addition to the two problems of double buffering and sequential VFS
operations execution described above, we are also working on the
overall reduction of CPU overheads to increase the system scalability.
We are exploring the effects of delaying some VFS
operations on non-authoritative branches.
In the future, we plan to add support for EAs,
dynamic adjustment of RAIF levels and other storage policies,
and provide advanced data recovery procedures in the kernel.
4 Preliminary Evaluation
We have evaluated RAIF performance during
different stages of the development process,
to identify possible problems early and update the
design as needed.
In this section we describe the performance of the current RAIF prototype
with data stored using levels 0 and 1.
We conducted our benchmarks on two 1.7GHz Pentium 4 machines with 1GB
of RAM.
The first machine was equipped with four Maxtor Atlas 15,000 RPM
18.4GB Ultra320 SCSI disks formatted with Ext2.
The second machine was used as an NFS server.
It had two 10GB Seagate U5 IDE drives formatted with Ext2.
Both machines were running Red Hat 9 with a vanilla 2.4.24 Linux kernel and were
connected via a dedicated 100Mbps link.
We remounted the lower file systems before every benchmark run to
purge the page cache. We ran each test at least ten times and used the
Student-t distribution to compute 95% confidence intervals for the
mean elapsed, system, user, and wait times. Wait time is the elapsed
time less CPU time used and consists mostly of I/O, but process
scheduling can also affect it. In each case the half-widths of the
confidence intervals were less than 5% of the mean.
We ran the following two benchmarks:
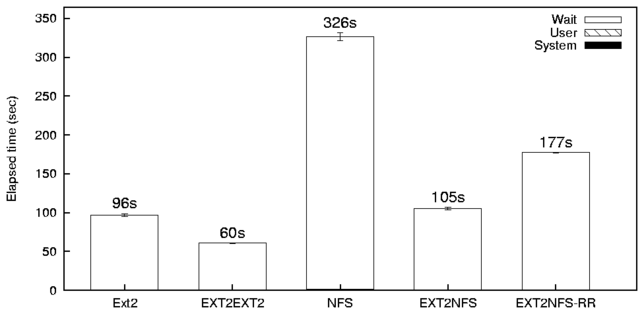
- Postmark [12] simulates the operation of electronic
mail servers. It performs a series of file
appends, reads, creations, and deletions. We configured Postmark to create
20,000 files, between 512-10K bytes, and perform 200,000
transactions. Create/delete and read/write operations were
selected with equal probability.
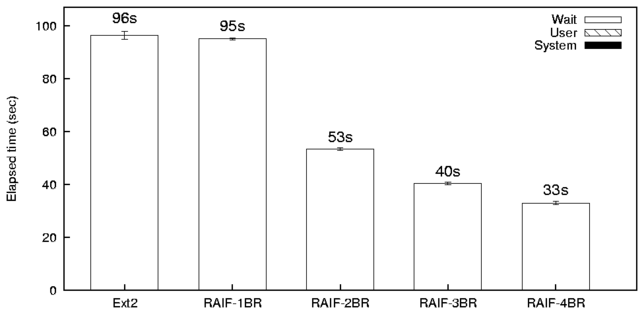
- RANDOM-READ is a benchmark designed to evaluate RAIF
under a heavy load of random data read operations.
It spawns 32 child processes and concurrently reads 32,000
randomly-located 512 byte blocks from 16GB files.
The load of the different lower branches fluctuates because of the
randomness of the read pattern. In particular, a branch may be idle
for some time, if all the reading processes have sent their requests
to the other branches. Our experiments showed that 32 processes are
sufficient to make these random fluctuations negligible.
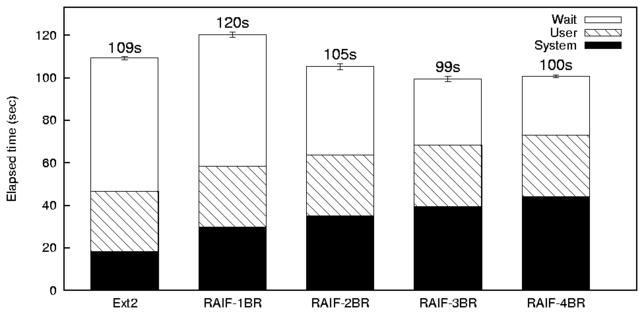
We call a test configuration RAIF-NBR, where
N is the number of branches.
We call RAIFL a RAIF file system where all files are stored
using RAIF level L.