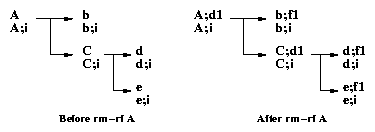
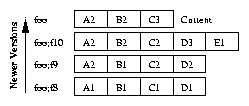

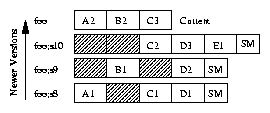
| Feature | WAFL | Elephant | CVFS | Versionfs | |
| 1 | File system implementation method | Disk based | Disk based | Disk based a | Stackable |
| 2 | Copy-on-Change | Yes | |||
| 3 | Comprehensive versioning (data, meta-data, etc.) | Yesb | |||
| 4 | Transparent support for compressed versions | Yes | |||
| 5 | Landmark retention policy | Yes | |||
| 6 | Number based retention policy | c | Yes | ||
| 7 | Time based retention policy | Yes | Yes | ||
| 8 | Space based retention policy | Yes | |||
| 9 | Unmodified applications can access previous versions | Yes | Yes | ||
| 10 | Per-user extension inclusion/exclusion list to version | Yes | |||
| 11 | Administrator can override user policies | Yes | |||
| 12 | Allows users to register their own reclamation policies | Yes | |||
| 13 | Version tagging | Yes |
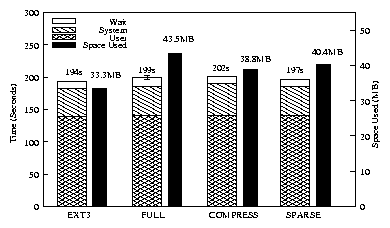
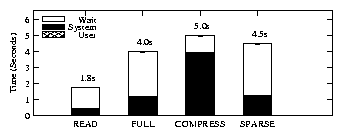
| Ext3 | Full | Compress | Sparse | |
| Elapsed | 193.7s | 199.1s | 201.6s | 196.6s |
| System | 43.4s | 45.2s | 50.3s | 45.4s |
| Wait | 10.8s | 12.7s | 10.7s | 10.8s |
| Space | 33.3MB | 43.5MB | 38.8MB | 40.4MB |
| Overhead over Ext3 | ||||
| Elapsed | - | 3% | 4% | 1% |
| System | - | 4% | 16% | 5% |
| Wait | - | 18% | -1% | 0% |
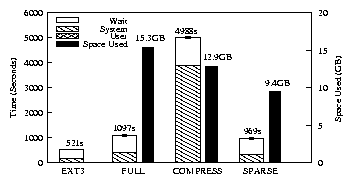
| Ext3 | Full | Compress | Sparse | |
| Elapsed | 521s | 1097s | 4988s | 969s |
| System | 128s | 368s | 3873s | 313s |
| Wait | 373s | 708s | 1093s | 634s |
| Space | 0GB | 15.34GB | 12.85GB | 9.43GB |
| Overhead over Ext3 | ||||
| Elapsed | - | 2.1 × | 9.6× | 1.9× |
| System | - | 2.9 × | 30.3× | 2.4× |
| Wait | - | 1.9 × | 2.9× | 1.7× |
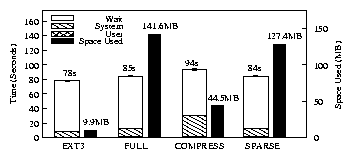
| Ext3 | Full | Compress | Sparse | |
| Elapsed | 78.0s | 84.6s | 93.6s | 84.2s |
| System | 7.5s | 11.2s | 28.9s | 11.3s |
| Wait | 69.6s | 72.6s | 63.8s | 72.0s |
| Space | 9.9MB | 141.6MB | 44.5MB | 127.4MB |
| Overhead over Ext3 | ||||
| Elapsed | - | 8% | 20% | 8% |
| System | - | 49% | 285% | 51% |
| Wait | - | 4% | -8% | 3% |
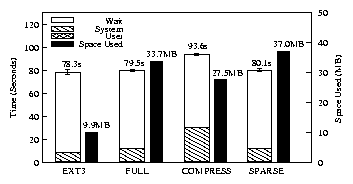
| Ext3 | Full | Compress | Sparse | |
| Elapsed | 78.3s | 79.5s | 93.6s | 80.1s |
| System | 7.7s | 11.3s | 29.2s | 11.6s |
| Wait | 69.9s | 67.4s | 63.6s | 67.6s |
| Space | 9.9MB | 33.7MB | 27.5MB | 37.0MB |
| Overhead over Ext3 | ||||
| Elapsed | - | 2% | 20% | 2% |
| System | - | 47% | 279% | 51% |
| Wait | - | -4% | -9% | -3% |
| Benchmark | FULL-COW | FULL-COC | COMPRESS-COW | COMPRESS-COC | SPARSE-COW | SPARSE-COC |
| Am-Utils copy | 370.7MB | 141.6MB | 168.4MB | 44.5MB | 370.9MB | 127.4MB |
| Am-Utils compile | 43.5MB | 43.5MB | 38.8MB | 38.8MB | 41.63MB | 40.4MB |