Our design goals for Usenetfs were:
The main idea for improving performance for large flat directories was to
break them into smaller ones. Since article names are composed of
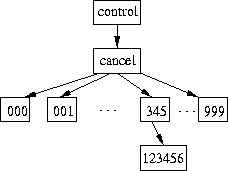
sequential numbers, we took advantage of that. We decided to create a
hierarchy consisting of one thousand directories as depicted in Figure
2.
Each operation that needs to manipulate a file name (such as lookup) performs name translation of the pathname to include the new subdirectory. For reading a whole directory (readdir), we would iterate over all of the subdirectories in order: 000, 001, ..., 999. Each entry read in these directories is returned to the caller of the system call.
Usenetfs needs to determine if a directory is managed or not. We decided to use a seldom used mode bit for directories, the setuid bit, to flag a directory as managed by Usenetfs. Using this bit allows the news administrator to control which directory is managed by Usenetfs and which is not, using a simple chmod command.
The next bit of design needed was how to handle files and directories whose names are not article numbers. Directories containing articles may include other directories representing other newsgroups, threads database files, etc. Usenetfs optimizes performance for the majority of files in the news spool -- articles. We decided not to complicate the code for the sake of these few non-article files: all non-articles are also moved one directory level downward into a special directory named aaa. For example, an original file control/cancel/foo is moved to control/cancel/aaa/foo.
We chose to move all files, articles, and non-articles, one level deeper because it was simpler to uniformly treat all files in a directory managed by Usenetfs. It simplifies lookups of the ``..'' parent directory. In order to maintain the illusion of a flat directory, Usenetfs also has to skip upward lookups of ``..'' one level up. For example, if a lookup for ``..'' happens in a managed subdirectory control/cancel/345/, that lookup must return the directory vnode for control/ and not for control/cancel/. In other words, the process performing a lookup (or chdir) for ``..'' for a managed directory control/cancel/ should not know that the underlying storage was different and should get back the expected directory control/.
An alternate solution to this problem that we considered was to manage article files based on their name, consisting only of digits, and assume that anything that does not consist of digits alone is not an article. However, there are unfortunately some newsgroups where part of the component name is all digits: alt.2600 and alt.autos.porsche.944 among others. Distinguishing between directories with numeric names and files with numeric names would require a stat(2) of each, and that would have slowed the performance of Usenetfs. Therefore we rejected this idea and opted for simplicity: move all articles and non-articles to a two-level deeper hierarchy.
The next issue was how to convert an unmanaged directory to be managed by Usenetfs -- creating some of the 000-999 subdirectories, and moving existing articles to their designated location. When measuring the number of articles in various newsgroups over a period of one month, we noticed that the large newsgroups remained large, while the small remained relatively small; no major changes were noticed other than a small but gradual increase in traffic. Newsgroups that were good candidates for management by Usenetfs were not likely to become low traffic overnight and will continue to have lots of traffic. Also, the number of such large newsgroups is small. In our news server for example, only 6 out of 11,017 newsgroups contained more than 10,000 articles each. Given that, we decided to make the process of turning directory management on/off an off-line process to be triggered by the news administrator with a script that we provide.
Alternately, we could have put all that code in the kernel, but that would have complicated the file system a lot, and would have cost us in significantly more development time, since kernel work is difficult. We did not feel that it was crucial to include this functionality at this stage, especially since we did not expect many directories to be managed.