In this section we discuss extensibility mechanisms for file systems, what would be required for such file systems to support SCAs, and other systems that provide some support for compression SCAs.
Traditional file system development is often done using low level file systems that interact directly with device drivers. Developing file systems in this manner is difficult and time-consuming, and result in code that is difficult to port to other systems. Stackable file systems build on a generalization of files called vnodes [KleimanKleiman1986], by allowing for modular, incremental development of file systems using a stackable vnode interface [Heidemann and PopekHeidemann and Popek1994,RosenthalRosenthal1992,Skinner and WongSkinner and Wong1993]. Stacking is a technique for modularizing file system functions by allowing one vnode interface implementation to call another, building upon existing implementations and changing only that which is needed. Stacking provides an infrastructure for the composition of multiple file systems into one.
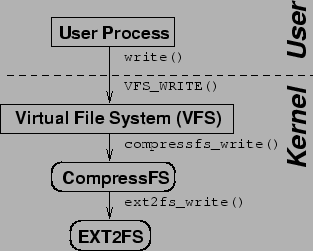 |
Figure 1 shows the structure for a simple single-level stackable compression file system called CompressFS. System calls are translated into VFS calls, which in turn invoke their CompressFS equivalents. CompressFS receives user data to be written. It compresses the data and passes it to the next lower layer, without any regard to what type of file system implements that layer.
Stackable file systems were designed to be modular and transparent: each layer is independent from the layers above and below it. In that way, stackable file system modules could be composed together in different configurations to provide new functionality. Moreover, stacking has the advantage of requiring no changes to lower-level file systems. A stackable file system can simply be mounted on top of any other file system. Not changing existing kernel components improves overall reliability and system stability because the less code changes--especially that supported by vendors--the more stable a new stackable file system can be.
Unfortunately, stacking poses problems for SCAs because the decoded data at the upper layer has different file offsets from the encoded data at the lower layer. CompressFS, for example, must know how much compressed data it wrote, where it wrote it, and what original offsets in the decoded file did that data represent. Those pieces of information are necessary so that subsequent reading operations can locate the data quickly. If CompressFS cannot find the data quickly, it may have to resort to decompression of the complete file before it can locate the data to read.
Therefore, to support SCAs in stackable file systems, a stackable layer must have some information about the encoded data--offset information. But a stackable file system that gets that information about other layers violates its transparency and independence. This is the main reason why past stacking works do not support SCAs. The challenge we faced was to add general-purpose SCA support to a stacking infrastructure without losing the benefits of stacking: a stackable file system with SCA support should not have to know anything about the file system it stacks on. That way it can add SCA functionality automatically to any other file system.
Compression file systems are not a new idea. Windows NT supports compression in NTFS [NagarNagar1997]. E2compr is a set of patches to Linux's Ext2 file system that add block-level compression [AyersAyers1997]. Compression extensions to log-structured file systems resulted in halving of the storage needed while degrading performance by no more than 60% [Burrows, Jerian, Lampson, and MannBurrows et al.1992]. The benefit of block-level compression file systems is primarily speed. Their main disadvantage is that they are specific to one operating system and one file system, making them difficult to port to other systems and resulting in code that is hard to maintain.
The ATTIC system demonstrated the usefulness of automatic compression of least-recently-used files [Cate and GrossCate and Gross1991]. It was implemented as a modified user-level NFS server. Whereas it provided portable code, in-kernel file systems typically perform better. In addition, the ATTIC system decompresses whole files which slows performance.
HURD [BushnellBushnell1994] and Plan 9 [Pike, Presotto, Thompson, and TrickeyPike et al.1990] have an extensible file system interface and have suggested the idea of stackable compression file systems. Their primary focus was on the basic minimal extensibility infrastructure; they did not produce any working examples of size-changing file systems.
Spring [Khalidi and NelsonKhalidi and Nelson1993,Mitchel, Giobbons, Hamilton, Kessler, Khalidi, Kougiouris, Madany, Nelson, Powell, and RadiaMitchel et al.1994] and Ficus [Heidemann and PopekHeidemann and Popek1994] discussed a similar idea for implementing a stackable compression file system. Both suggested a unified cache manager that can automatically map compressed and uncompressed pages to each other. Heidemann's later work [Heidemann and PopekHeidemann and Popek1995] provided additional details on mapping cached pages of different sizes. He mentioned a ``prototype compression layer'' built during a class project. In personal communications with the author, we were told that this prototype was implemented as a block-level compression file system, not a stackable one. Unfortunately, no demonstration of these ideas for compression file systems in a stacking environment was available from either of these works. In addition, no consideration was given to arbitrary SCAs and how to efficiently handle common file operations such as appends, looking up file attributes, etc.
Another transparent compression method possible is in user level. Zlibc is a pre-loadable shared library that allows executables to uncompress the data files that they need on the fly [KnaffKnaff1997]. It is slow because it runs in user level, it only works on whole files, and it can only decompress files. Furthermore, it has to decompress the whole file before it can be used. Our system is much more flexible, performs well, can work with parts of files or whole files, and we support all file system operations transparently.
GNU zip (Gzip)) [Deutsch and GaillyDeutsch and Gailly1996a,GaillyGailly2000] itself maintains some information on the structure of its compressed data. This information includes the unencoded length of the file, the original file name, and a checksum of the encoded data. The information is useful, but is insufficient for the needs of a file system. Gzip, for example, does not provide support for random-access reading, a requirement for a compressed file system. With Gzip, compressed data must be decompressed sequentially from beginning to end.