Our work is implemented in and on SunOS 4.1.2. We have changed the kernel's client-side NFS implementation, and outside the operating system we have made use of the Amd automounter and the RLP resource location protocol. Each is explained briefly below.
Particulars about the NFS protocol and implementation are widely known and published [Blaze92,Hitz94,Juszczak89,Juszczak94,Keith90,Keith93,Kleiman86,Macklem91,Pawlowski94,Rosen86,Rosenthal90,Sandberg85a,Sandberg85b,Schaps93,Srinivasan89,Stein87,Stern92,Sun85,Sun86,Sun89,Walsh85,Watson92].
For the purpose of our presentation, the only uncommon facts that need to be known are:
We have made substantial alterations to au_lookuppn(), and slight alterations to rfscall(), nfs_mount(), nfs_unmount() and copen().2.1
We added two new system calls: one for controlling and querying the added structures in the kernel (nfsmgr_ctrl()), and the other for debugging our code (nfsmgr_debug()). Additional minor changes in support of debugging were made to ufs_mount() and tmp_mount().
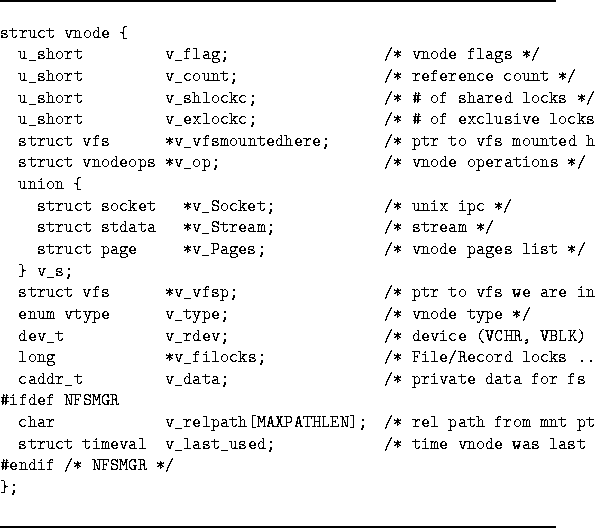
Finally, we added fields to three major kernel data structures: vfs and vnode structures and the open file table. Below we show these modified structures and describe their most relevant fields.
A vfs is the structure for a Virtual File System [Kleiman86]. A singly-linked list of such structures exists in the kernel, the head of which is the global rootvfs -- a hand-crafted structure for the root filesystem. This structure was substantially modified; see Figure 2.1.2.2 That is not surprising since most of our work is related to managing filesystems as a whole.
The fields of interest are:
The fields specific to our work are described in Section 3.4.1.1.
This structure was only slightly modified; see Figure 2.2. A vnode exists for each open file or directory.2.3 The parts of the kernel that access vnodes directly are the filesystem sections. Therefore a vnode is a representation of open files from the filesystem's point of view. Only one vnode exists for each open file, no matter how many processes have opened it, or even if the file has several names (via hard or symbolic links).
Structure fields relevant to our work are:
The fields specific to our work are described in Section 3.4.1.2.
This structure was also only slightly modified; see Figure 2.3. A file structure exists for each file opened by a process. The kernel modules that access this structure directly are those that handle processes and user contexts. Therefore a struct file is a representation of open files from the user's and process' points of view. The various complex interactions between struct file and struct vnode are de-mystified after the brief explanation of various fields in this structure.
Fields of use to us are:
The fields specific to our work are described in Section 3.4.1.3.
There is only one Global Open File Table in the kernel. It has a limited size with some provisions to extend it dynamically if need be. Each u (user-specific) structure has an array of pointers to its open files. These u.u_pofile_arr[idx] are pointers into the global open file table.
When two different processes open the same file (by name or by link) they get two different struct file entries in the global open file table. Each file structure contains an f_offset field so that each process can maintain a different offset. Each file structure however, will have an f_data field that points to the same vnode.
The vnode structure contains the flags needed for performing advisory locking [SMCC90a,SMCC90b], and has a reference count of how many processes opened it.
Things get more complicated when a process opens a file then forks. The child inherits the same file structure pointer that the parent has. That means that if the child seeks elsewhere into the file, the parent will too, since they have the same f_offset field!2.5
The last bit of missing information is how does the kernel tell that more than one process is sharing the same entry in the global file table. The answer is that each file structure contains an f_count field -- a reference count similar to, but different from, the one in the vnode structure.
We use the RLP resource location protocol [Accetta83] when seeking a replacement file system. RLP is a general-purpose protocol that allows a site to send broadcast or unicast request messages asking either of two questions:
A service is named by the combination of its transport service (e.g., TCP), its well-known port number as listed in /etc/services, and an arbitrary string that has meaning to the service. Since we search for an NFS-mountable file system, our RLP request messages contain information such as the NFS transport protocol (UDP [rfc0768]), port number (2049) and service-specific information such as the name of the root of the file system.
Amd [Pendry91,Stewart93] is a widely-used automounter daemon. Its most common use is to demand-mount file systems and later unmount them after a period of disuse; however, Amd has many other capabilities.
Amd operates by mimicking an NFS server. An Amd process is identified to the kernel as the ``NFS server'' for a particular mount point. The only NFS calls for which Amd provides an implementation are those that perform name resolution: lookup, readdir, and readlink. Since a file must have its name resolved before it can be used, Amd is assured of receiving control during the first use of any file below an Amd mount point. Amd checks whether the file system mapped to that mount point is currently mounted; if not, Amd mounts it, makes a symbolic link to the mount point, and returns to the kernel. If the file system is already mounted, Amd returns immediately.
An example, taken from our environment, of Amd's operation is the following. Suppose /u is designated as the directory in which all user file systems live; Amd services this directory. At startup time, Amd is instructed that the private mount point (for NFS filesystem which it will mount) is /n. If any of the three name binding operations mentioned above occurs for any file below /u, then Amd is invoked.2.6 Amd consults its maps, which indicate that /u/foo is available on server bar. This file system is then mounted locally at /n/bar/u/foo and /u/foo is made a symbolic link to /n/bar/u/foo. (Placing the server name in the name of the mount point is purely a configuration decision, and is not essential.)
Our work is not dependent on Amd; we use it for convenience. Amd typically controls the (un)mounting of all file systems on the client machines on which it runs, and there is no advantage to our work in circumventing it and performing our own (un)mounts.
Amd does not already possess the capabilities we need, nor is our work a simple extension to Amd. Our work adds at least three major capabilities:
Many systems provide a tool, like nfsstat, that returns timing information gathered by the kernel. However, nfsstat is inadequate because it is not as accurate as our measurements, and provides weighted average response time rather than measured response time. Our method additionally is less sensitive to outliers, and measures both short-term and long-term performance.
Amd might be considered the more ``natural'' place for our user-level code, since Amd makes similar mount decisions based on some criteria. Some coding could have been saved and speedups made if we placed our user-level management code inside Amd. However, we saw two main problems with this approach: